The post Predict Values From Images With Image Regression appeared first on Ximilar: Visual AI for Business.
]]>Let’s take a look at what image regression is and how it works, including examples of the most common applications. More importantly, I will tell you how you can train your own regression system on a no-code computer vision platform. As more and more customers seek to extract information from pictures, this new feature is sure to provide Ximilar’s customers with the tools they need to stay ahead of the curve in today’s highly competitive AI-driven market.
What is the Difference Between Image Categorization and Regression?
Image recognition models are ideal for the recognition of images or objects in them, their categorization and tagging (labelling). Let’s say you want to recognize different types of car tyres or their patterns. In this case, categorization and tagging models would be suitable for assigning discrete features to images. However, if you want to predict any continuous value from a certain range, such as the level of tyre wear, image regression is the preferred approach.
Image regression is an advanced machine-learning technique that can predict continuous values within a specific range. Whenever you need to rate or evaluate a collection of images, an image regression system can be incredibly useful.
For instance, you can define a range of values, such as 0 to 5, where 0 is the worst and 5 is the best, and train an image regression task to predict the appropriate rating for given products. Such predictive systems are ideal for assigning values to several specific features within images. In this case, the system would provide you with highly accurate insights into the wear and tear of a particular tyre.

How to Train Image Regression With a Computer Vision Platform?
Simply log in to Ximilar App and go to Categorization & Tagging. Upload your training pictures and under Tasks, click on Create a new task and create a Regression task.
You can train regression tasks and test them via the same front end or with API. You can develop an AI prediction task for your photos with just a few clicks, without any coding or any knowledge of machine learning.
This way, you can create an automatic grading system able to analyze an image and provide a numerical output in the defined range.
Use the Same Training Data For All Your Image Classification Tasks
Both image recognition and image regression methods fall under the image classification techniques. That is why the whole process of working with regression is very similar to categorization & tagging models.
Both technologies can work with the same datasets (training images), and inputs of various image sizes and types. In both cases, you can simply upload your data set to the platform, and after creating a task, label the pictures with appropriate continuous values, and then click on the Train button.

Apart from a machine learning platform, we offer a number of AI solutions that are field-tested and ready to use. Check out our public demos to see them in action.
If you would like to build your first image classification system on a no-code machine learning platform, I recommend checking out the article How to Build Your Own Image Recognition API. We defined the basic terms in the article How to Train Custom Image Classifier in 5 Minutes. We also made a basic video tutorial:
Neural Network: The Technology Behind Predicting Range Values on Images
The most simple technique for predicting float values is linear regression. This can be further extended to polynomial regression. These two statistical techniques are working great on tabular input data. However, when it comes to predicting numbers from images, a more advanced approach is required. That’s where neural networks come in. Mathematically said, neural network “f” can be trained to predict value “y” on picture “x”, or “y = f(x)”.
Neural networks can be thought of as approximations of functions that we aim to identify through the optimization on training data. The most commonly used NNs for image-based predictions are Convolutional Neural Networks (CNNs), visual transformers (VisT), or a combination of both. These powerful tools analyze pictures pixel by pixel, and learn relevant features and patterns that are essential for solving the problem at hand.
CNNs are particularly effective in picture analysis tasks. They are able to detect features at different spatial scales and orientations. Meanwhile, VisTs have been gaining popularity due to their ability to learn visual features without being constrained by spatial invariance. When used together, these techniques can provide a comprehensive approach to image-based predictions. We can use them to extract the most relevant information from images.
What Are the Most Common Applications of Value Regression From Images?
Estimating Age From Photos
Probably the most widely known use case of image regression by the public is age prediction. You can come across them on social media platforms and mobile apps, such as Facebook, Instagram, Snapchat, or Face App. They apply deep learning algorithms to predict a user’s age based on their facial features and other details.

Needless to say, these plugins are not always correct and can sometimes produce biased results. Despite this limitation, various image regression models are gaining popularity on various social sites and in apps.
Ximilar already provides a face-detection solution. Models such as age prediction can be easily trained and deployed on our platform and integrated into your system.
Value Prediction and Rating of Real Estate Photos
Pictures play an essential part on real estate sites. When people are looking for a new home or investment, they are navigating through the feed mainly by visual features. With image regression, you are able to predict the state, quality, price, and overall rating of real estate from photos. This can help with both searching and evaluating real estate.

Custom recognition models are also great for the recognition & categorization of the features present in real estate photos. For example, you can determine whether a room is furnished, what type of room it is, and categorize the windows and floors based on their design.
Additionally, a regression can determine the quality or state of floors or walls, as well as rank the overall visual aesthetics of households. You can store all of this information in your database. Your users can then use such data to search for real estate that meets specific criteria.

Determining the Degree of Wear and Tear With AI
Visual AI is increasingly being used to estimate the condition of products in photos. While recognition systems can detect individual tears and surface defects, regression systems can estimate the overall degree of wear and tear of things.
A good example of an industry that has seen significant adoption of such technology is the insurance industry. For example, startups-like Lemonade Inc, or Root use AI when paying the insurance.
With custom image recognition and regression methods, it is now possible to automate the process of insurance claims. For instance, a visual AI system can indicate the seriousness of damage to cars after accidents or assess the wear and tear of various parts such as suspension, tires, or gearboxes. The same goes with other types of insurance, including households, appliances, or even collectible & antique items.
Our platform is commonly utilized to develop recognition and detection systems for visual quality control & defect detection. Read more in the article Visual AI Takes Quality Control to a New Level.
Automatic Grading of Antique & Collectible Items Such as Sports Cards
Apart from car insurance and damage inspection, recognition and regression are great for all types of grading and sorting systems, for instance on price comparators and marketplaces of collectible and antique items. Deep learning is ideal for the automatic visual grading of collector items such as comic books and trading cards.
By leveraging visual AI technology, companies can streamline their processes, reduce manual labor significantly, cut costs, and enhance the accuracy and reliability of their assessments, leading to greater customer satisfaction.
Automatic Recognition of Collectibles
Ximilar built an AI system for the detection, recognition and grading of collectibles. Check it out!

Food Quality Estimation With AI
Biotech, Med Tech, and Industry 4.0 also have a lot of applications for regression models. For example, they can estimate the approximate level of fruit & vegetable ripeness or freshness from a simple camera image.

For instance, this Japanese farmer is using deep learning for cucumber quality checks. Looking for quality control or estimation of size and other parameters of olives, fruits, or meat? You can easily create a system tailored to these use cases without coding on the Ximilar platform.
Build Custom Evaluation & Grading Systems With Ximilar
Ximilar provides a no-code visual AI platform accessible via App & API. You can log in and train your own visual AI without the need to know how to code or have expertise in deep learning techniques. It will take you just a few minutes to build a powerful AI model. Don’t hesitate to test it for free and let us know what you think!
Our developers and annotators are also able to build custom recognition and regression systems from scratch. We can help you with the training of the custom task and then with the deployment in production. Both custom and ready-to-use solutions can be used via API or even deployed offline.
The post Predict Values From Images With Image Regression appeared first on Ximilar: Visual AI for Business.
]]>The post How to Build Your Own Image Recognition API? appeared first on Ximilar: Visual AI for Business.
]]>For example, recently, I had a conversation with a client who said that Google Vision didn’t work for him, and it returned non-relevant tags. The problem was not the API but the approach to it. He employed a few students to do the labelling job and create an image classifier. However, the results were not good at all. After showing him our approach, sharing some tips and simple rules, he got better classification results almost immediately. This post should serve as a comprehensive guide for those, who build their own image classifiers and want to get the most out of it.
How to Begin
Image recognition is based on the techniques of machine learning and computer vision. It is able to categorize and tag images with tags describing the attributes recognized in them. You can read everything about the service and its possibilities here.
To train your own Image Recognition models and create a system accessible through API, you will first need to upload a set of training images and create your image recognition tasks (models). Then you will use the training set to train the models to categorize the images.
If you need your images to be tagged, you should upload or create a set of tags and train tagging tasks. As the last step, you can combine these tasks into a Flow, and modify or replace any of them anytime due to its modular structure. You can then gradually improve your accuracy based on testing, evaluation metrics and feedback from your customers. Let’s have a look at the basic rules you should follow to reach the best results.
The Basic Rules for Image Recognition Models Training
Each image recognition task contains at least two labels (classes, categories) – e.g., cats and dogs. A classic image recognition model (task) assigns one label to each image – so the image is either a cat or dog. In general, the more classes you have, the more data you will need to teach the neural network to predict labels.

The training images should represent the real data that will be analyzed in a production setting. For example, if you aim to build a medical diagnostic tool helping radiologists identify the slightest changes in the lung tissue, you need to assemble a database of x-ray images with proven pathological findings. For the first training of your task, we recommend sticking to these simple rules:
- Start with binary classification (two labels) – use 50–100 images/label
- Use about 20 labels for basic and 100 labels for more complex solutions
- For well-defined labels use 200+ images/label
- For hard to recognize labels add 100+ images/label
- Pattern recognition – for structures, x-ray images, etc. use 50–100 images/label
Always keep in mind, that training one task with hundreds of labels on small datasets almost never works. You need at least 20 labels and 100+ images per label to start with to achieve solid results. Start with the recommended counts, and then add more if needed.
The Difference Between Testing & Production
The users of Ximilar App can train tasks with a minimum of 20 images per label. Our platform automatically divides your input data into two datasets – training & test set, usually in a ratio of 80:20. The training set is used to optimize the parameters of the classifier. During the training, the training images are augmented in several ways to extend the set.
The test data (about 20 %) are then used to validate and measure accuracy by simulating how the model will perform in production. You can see the accuracy results on the Task dashboard in Ximilar App. You can also create an independent test dataset and evaluate it. This is a great way to get accurate results on a dataset that was not seen by the model in the training before you actually deploy it.
Remember, the lower limit of 20 images per label usually leads to weak results and low accuracy. While it might be enough for your testing, it won’t be enough for production. This is also called overfitting. Most of the time the accuracy in Ximilar is pretty high, easily over 80 % for small datasets. However, it is common in machine learning to use more images for more stable and reliable results in production. Some tasks need hundreds or thousands of images per label for the good performance of your production model. Read more about the advanced options for training.
The Best Practices in Image Recognition Training
Start With Fewer Categories
I usually advise first-time users to start with up to 10 categories. For example, when building an app for people to recognize shoes, you would start with 10 shoe types (running, trekking, sneakers, indoor sport, boots, mules, loafers …). It is easier to train a model with 10 labels, each with 100 training images of a shoe type, than with 30 types. You can let users upload new shoe images. This way, you can get an amazing training dataset of real images in one month and then gradually update your model.
Use Multiple Recognition Tasks With Fewer Categories
The simpler classifiers can be incredibly helpful. Actually, we can end up with more than 30 types of shoes in one model. However, as we said, it is harder to train such a model. Instead, we can create a system with better performance if we create one model for classifying footwear into main types – Sport, Casual, Elegant, etc. And then for each of the main types, we create another classifier. So for Sport, there will be a model that classifies sports shoes to Running shoes, Sneakers, Indoor shoes, Trekking shoes, Soccer shoes, etc.
Use Binary Classifiers for Important Classes
Imagine you are building a tagging model for real estate websites, and you have a small training dataset. You can first separate your images into estate types. For example, start with a binary classifier that separates images to groups “Apartment” and “Outdoor house”. Then you can train more models specifically for room types (kitchen, bedroom, living room, …), apartment features, room quality, etc. These models will be used only if the image is labelled as “Apartment”.
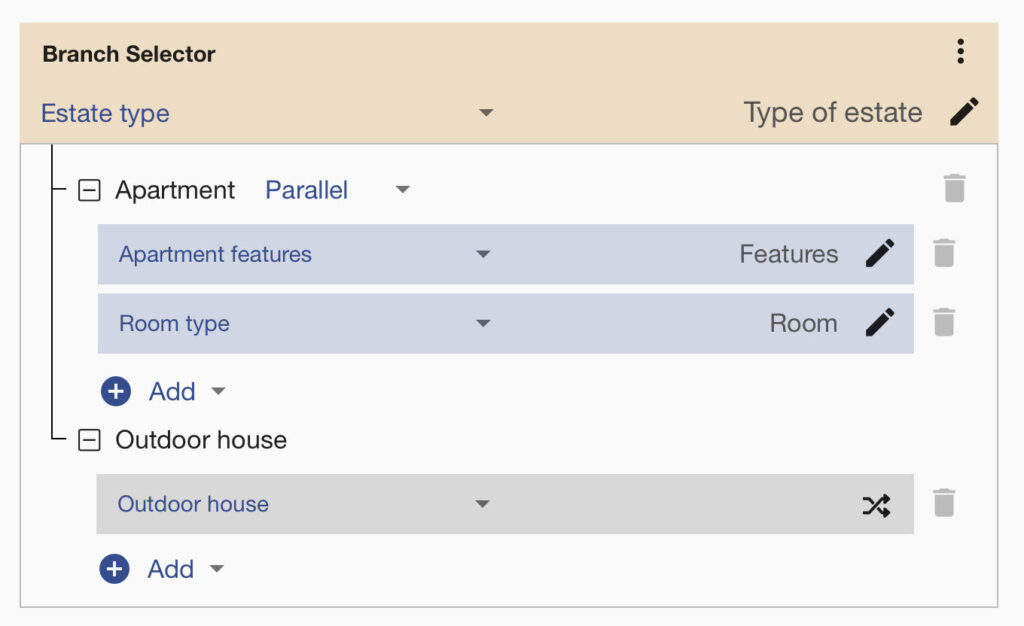
You can connect all these tasks via the Flows system with a few clicks. This way, you can chain multiple image recognition models in one API endpoint and build a powerful visual AI. Typical use cases for Flows are in the e-commerce and healthcare fields. Systems for fashion product tagging can also contain thousands of labels. It’s hard to train just one model with thousands of labels that will have good accuracy. But, if you divide your data into multiple models, you will achieve better results in a shorter time! For labelling work, you can use our image Annotation system if needed.
Choose Your Training Images Wisely
Machine learning performs better if the distribution of training and evaluated pictures is even. It means that your training pictures should be very visually similar to the pictures your model will analyze in a production setting. So if your model will be used in CCTV setting, then your training data must come from CCTV cameras. Otherwise, you are likely to build a model that has great performance on training data, but it completely fails when used in production.
The same applies to Real Estate and other fields. If the system analyzes images of real estate that were not made only by professional photographers, then you need to include photos from smartphones, with bad lighting, blurry images, etc.

Improving the Accuracy of the System
When clicking on the training button on the task page, the new model is created and put in the training queue. If you upload more data or change labels, you can train a new model. You can have multiple versions of them and deploy to the API only specific version that works best for you. Down on the task page, you can find a table with all your trained models (only the last 5 are stored). For each trained model, we store several metrics that are useful when deciding which model to pick for production.
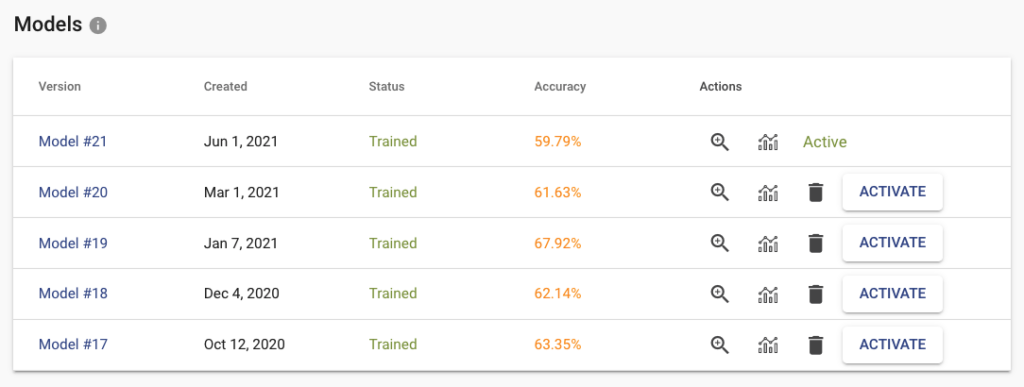
Inspect the Results and Errors
Click on the zoom icon in the list of trained models to inspect the results. You can see the basic metrics: Accuracy, Recall, and Precision. Precision tells you what is the probability that the model is right if it predicts a specific label. Recall tells you how likely is the prediction correct. If we have high recall but lower precision for the label “Apartment” from our real estate example, then the model is probably predicting on every image that it is “Apartment” (even on the images that should be “Outdoor house”). The solution is probably simple – just add more pictures that represent “Outdoor house”.
The Confusion matrix shows you which labels are easily confused by the trained model. These labels probably contain similar images, and it is therefore hard for the model to distinguish between them. Another useful component is Failed Images (misclassified) that show you the model’s mistake on your data. With Failed images, you can also see labelling mistakes in your data and fix them immediately. All of these features will help you build a more reliable model with good performance.
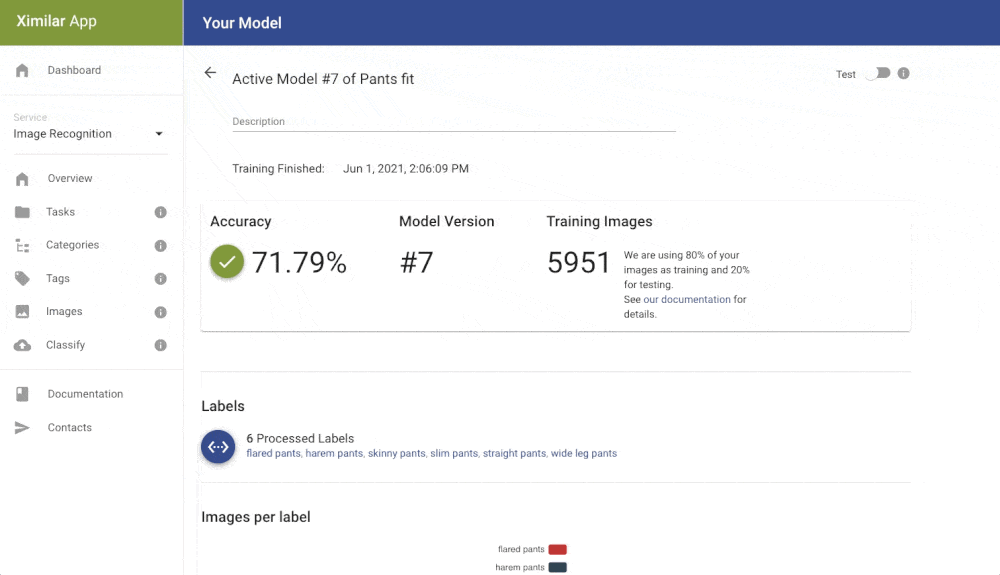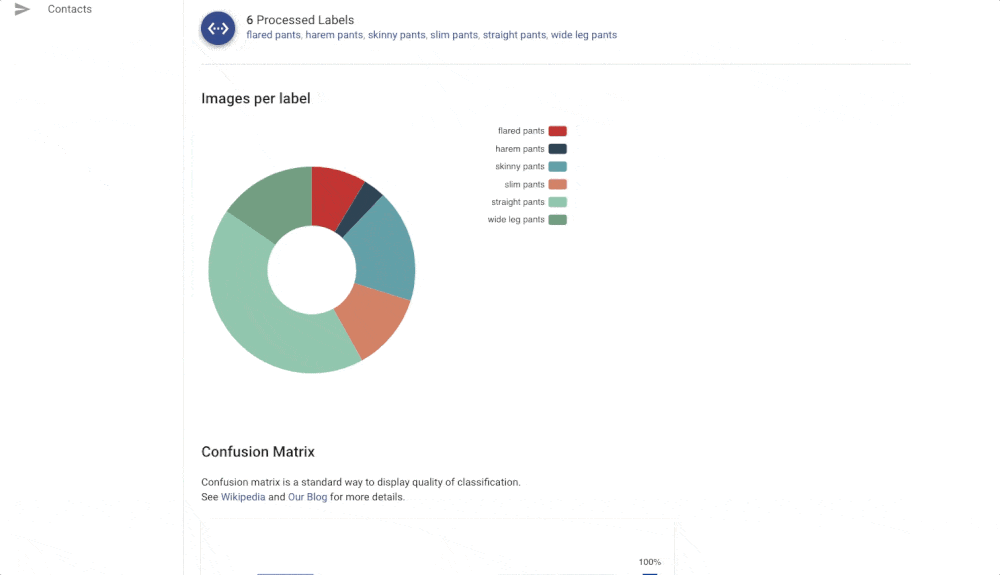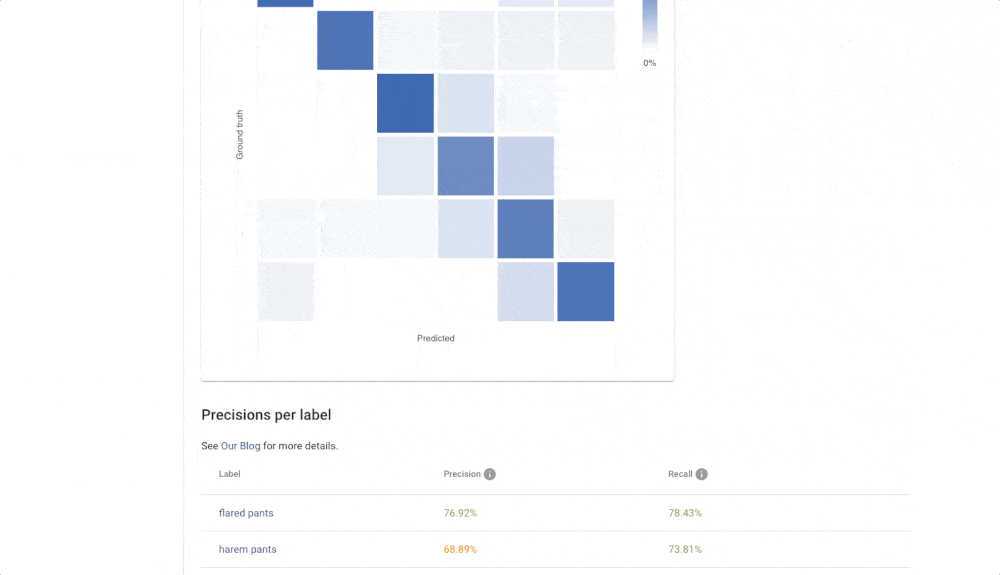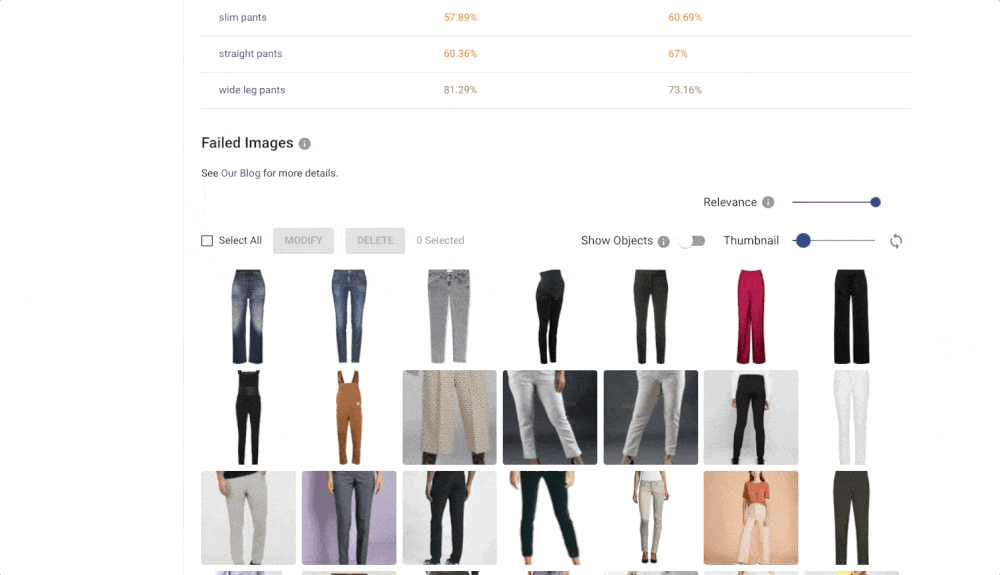
Reliability of the Image Recognition Results
Every client is looking for reliability and robustness. Stay simple if you aim to reach high accuracy. Build models with just a few labels if you can. For more complex tagging systems use Flows. Building an image classifier with a limited number of training images needs an iterative approach. Here are a few tips on how to achieve high accuracy and reliable results:
- Break your large task into simple decisions (yes or no) or basic categories (red, blue and green)
- Make fewer categories & connect them logically
- Use general models for general categories
- Make sure your training data represent the real data your model will analyze in production
- Each label should have a similar amount of images, so the data will be balanced
- Merge very close classes (visually similar), then create another task only for them, and connect it via Flows
- Use both human and UI feedback to improve the quality of your dataset – inspect evaluation metrics like Accuracy, Precision, Recall, Confusion Matrix, and Failed Images
- Always collect new images to extend your dataset
Summary for Training Image Recognition Models
Building an image classifier requires a proper task definition and continuous improvements of your training dataset. If the size of the dataset is challenging, start simple and gradually iterate towards your goal. To make the basic setup easier, we created a few step-by-step video tutorials. Learn how to deploy your models for offline use here, check the other guides, or our API documentation. You can also see for yourself how our pre-trained models perform in the public demo.
We believe that with the Ximilar platform, you are able to create highly complex, customizable, and scalable solutions tailored to the needs of your business – check the use cases for quality control, visual search engines or fashion. The basic features in our app are free, so anyone can try it. Training of image recognition models is also free with Ximilar platform. You are simply paying only for calling the model for prediction. We are always here to discuss your custom projects and all the challenges in person or on a call. If you have any questions, feel free to contact us.
The post How to Build Your Own Image Recognition API? appeared first on Ximilar: Visual AI for Business.
]]>The post Introducing Tags, Categories & Image Management appeared first on Ximilar: Visual AI for Business.
]]>New Label Types: Categories & Tags
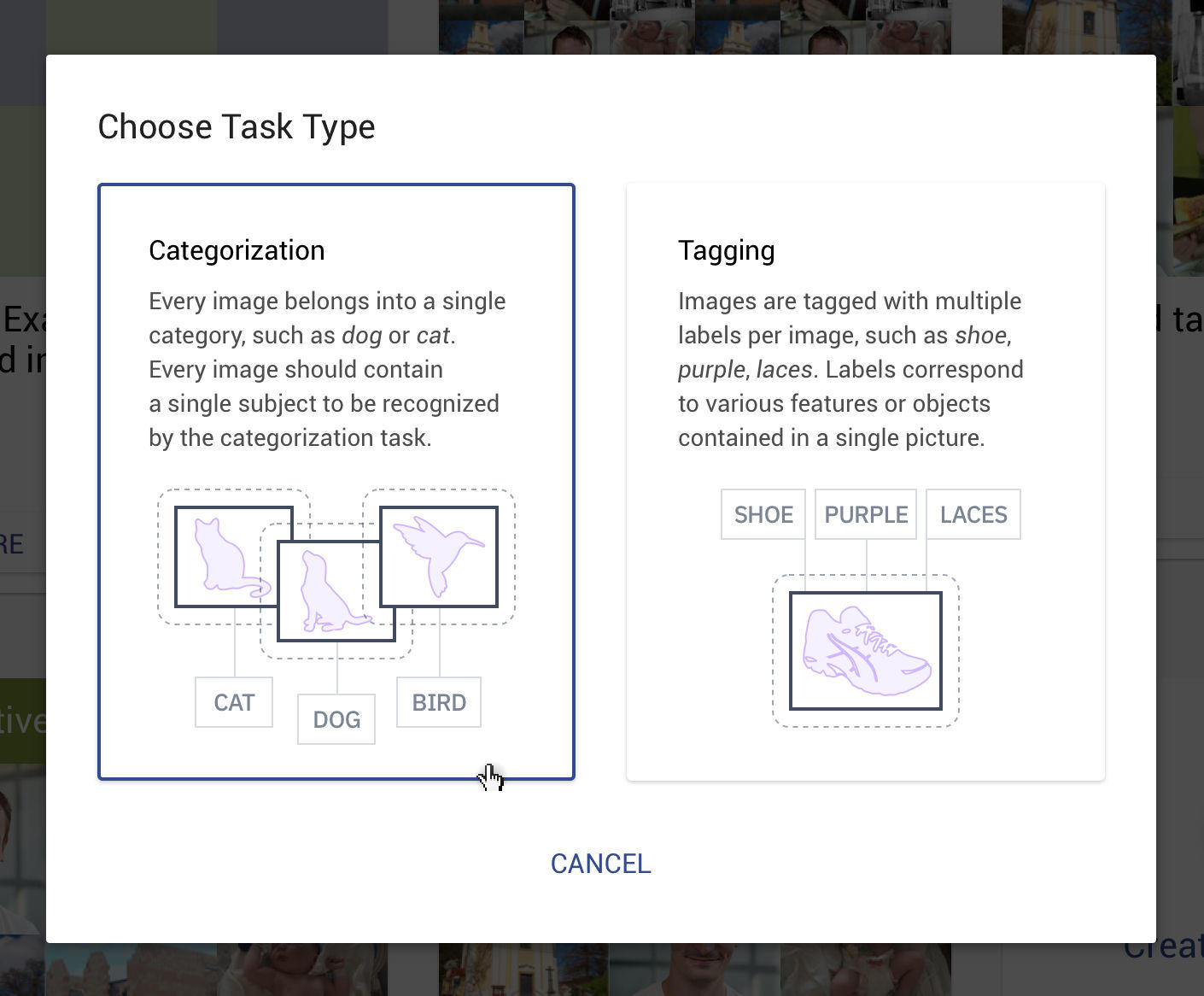
Benefit: Linking Tags with Categories
- Automatically categorize photos by room type — living room, bedroom, kitchen, outdoor house. At the same time, also:
- Recognize different features/objects in the images — bed, cabinet, wooden floor, lamp, etc.
So far, customers had to upload — often the same — training images separately into each label.
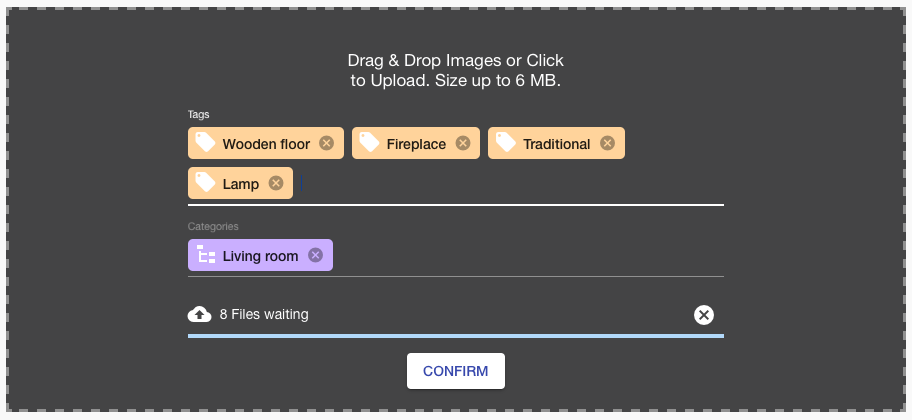
This upgrade makes this way easier. The new Ximilar App section Images allows you to upload images once and assign them to several Categories and Tags. You can easily modify the categories and tags of each image there. Either one by one or in bulk. There can be thousands of images in your workspace. So you can also filter images by their tags/categories and do batch processing on selected images. We believe that this will speed up the workflow of building reliable data for your tasks.
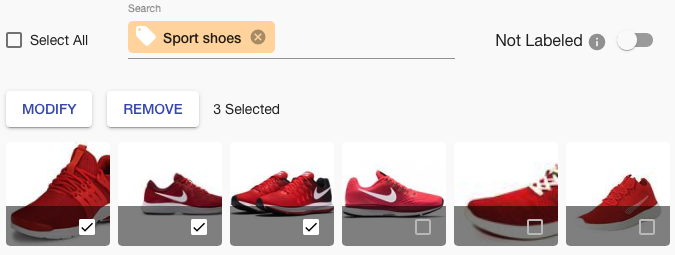
Improved Search
Some of our customers have hundreds of Labels. With a growing number of projects, it started to be hard to orient all Labels, Tags, and Tasks. That is why there is now a search bar at the top of the screen, which helps you find desired items faster.
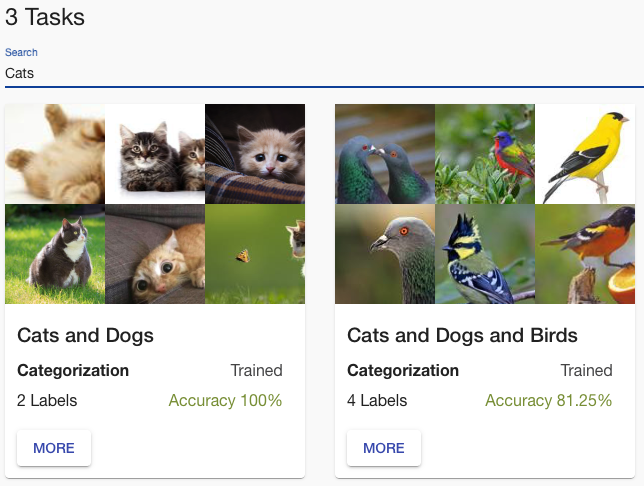
Updated Insights
Upcoming Features
- Workspaces — to clearly split work in different areas
- Rich statistics — number of API calls, amount of credits, per task, long-term/per-month/within-week/hourly and more.
The post Introducing Tags, Categories & Image Management appeared first on Ximilar: Visual AI for Business.
]]>The post How Does Machine Learning Work? Like a Brain! appeared first on Ximilar: Visual AI for Business.
]]>I could point to dozens of articles about machine learning and convolutional neural networks. Every article describes different details. Sometimes too many details are mentioned, so I decided to write my own article using the parallel of machine learning and the human brain. I will not touch any mathematics or deep learning details. The goal is to stay simple and help people experimenting with Ximilar to meet their goals.
Introduction
Machine learning provides computers with the ability to learn without being explicitly programmed.
For images: We want something that can look at a set of images and remember the patterns. When we expose a new image to our smart “model” it will “guess” what is on the image. That’s how people learn!
I mentioned two important words:
- Model — is what we call machine learning algorithms. It is not coded anymore (if green, then grass). It is a structure that can learn and generalize (small, rounded, green is apple).
- Guess — we are not in a binary world. Now, we moved into the probability domain. We receive a likelihood of an image to be an apple.
Deeper But Still Simple
A model is like a child’s brain. You show it an apple to a kid and say, “This is an apple”. Repeating it 20 times, a connection in its brain is established and it can now recognize apples. What is important at the beginning, it can not differentiate small details. The small ball in your hand is an apple because it follows the same pattern (small, rounded, green).
The set of images shown to the kid is called the training dataset.
The brain is a model, and it can recognize only categories from image datasets. It is made of layers and connections. This makes it similar to our brain structure. Different parts of the network are learning different abstract patterns.
Supervised learning means we have to say “This is an apple” and add visual information to it. We are adding a label to each image.
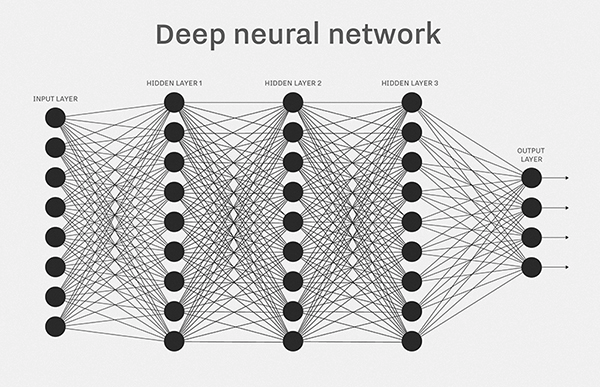
Simple deep learning network
Evaluation – Model Accuracy
In human terms, this is like exam time. At school, we learn a lot of information and general concepts. To understand how much we actually know, the teacher prepares a set of questions we have not seen in study books. Then we evaluate our brain and we know 9 of 10 questions are answered right.
Teachers’ questions are what we call the testing dataset. It is usually parted from the training dataset before training (20% of provided pictures in our case).
Accuracy is the number of images we answer right (in percent). What is important: we do not care how sure he is about his answer. We only care about the final answers.
Limits of Computers
Why don’t we have computers with human-level skills yet? Because the brain is the most powerful computer. It has amazing processing power, huge memory and some magical sauce we don’t even understand.
Our computer models are limited in memory and computational power. We are fine with storage memory but short with superfast memory accessible by processors. Power is limited by heat, technology, price etc.
Bigger models can hold more information but take longer to train. This makes the AI development in 2017 focus on:
- making the models smaller,
- less computationally intensive,
- able to learn more information.
Connection to Custom Image Recognition
This technology is what drives our custom image classification API. People can build an image recognizer without deep knowledge in a few minutes. Sometimes clients ask me if we can recognize 10,000 categories, having one training image of each. Imagine the kid’s brain learning this. It is nearly impossible. The idea is, that the more categories you want your child to know, the more images it has to see. It takes ages for our brains to develop and understand the world. Same as the child starts with basic objects, and starts with basic categories.
What the child is confident about is good/bad. Teaching models to differentiate good from bad is very accurate and does not need many images.
Summary
I tried to simplify machine learning to a visual task only and compare it with something we all know. In Ximilar we often think of the human brain while experimenting with new models and processing pipelines. I will be happy to hear some feedback from you.
This article was originally published by David Rajnoch.
The post How Does Machine Learning Work? Like a Brain! appeared first on Ximilar: Visual AI for Business.
]]>